# Set up your data source
The Data Sources setting allows you to specify one or more sources for performing SQL queries. You can add as many data sources as required to this fixed list during the recipe setup. You cannot add data sources after the recipe is activated.
Select Add data source to add one or more data sources.
Configure the following fields:
- Data source name
- Specify an alias name for the data source, such as accounts or employees, to reference in the query.
- Data source type
- Choose the data source type from which SQL Transformations fetches data. Available options include Content stream, FileStorage file, and Data table.
- Content stream
- Use this option if your data source is a CSV content stream. You can pass the CSV content's datapill from an upstream action, such as bulk actions or file contents from a file connector.
- FileStorage file
- Choose this option if your data is in a file within Workato FileStorage. You can enter the file's path directly or use a datapill from upstream FileStorage actions, such as Search files or Get contents.
- Data table
- Choose this option to fetch data directly from a data table within Workato's Data Tables. This setting allows you to retrieve data from tables configured within Workato without additional setup requirements.
- Data table (Data tables only)
- After selecting Data table as the data source type, choose the specific data table you plan to use from the list of tables available in Workato’s Data tables. This step determines the source of the data for your SQL queries.
- File format
- Select the file format, either CSV or Excel, when using Content stream or FileStorage file as your data source type. This choice determines the additional configuration options available for your data source.
- Worksheet (Excel files only)
- Enter the name of the Excel worksheet where the data is available and from which you plan to retrieve data.
- Range (Excel files only)
- Specify the cell range within the Excel worksheet you plan to retrieve data from, such as
B5:C20. Ensure to ignore the header row when you provide the range. - Data schema
- The Data schema is essential for querying the data provided. To establish the schema, provide the column names from your CSV or Excel file. You can use the Use a sample CSV file feature to automatically input column names for CSV files. For Excel files, manually enter the column names to tailor the schema to your specific requirements.
- Ignore CSV header row (CSV files only)
- Set this option to Yes to ignore the header row in your CSV contents. The default setting is set to No.
- Column delimiter (CSV files only)
- Select the delimiter that your CSV data uses, such as a , (comma) or ; (semicolon).
RESERVED CHARACTER USAGE
Avoid using the @ character at the beginning of table and column names in Data Tables. It is reserved in SQL and may cause errors during query execution.
HOW ARE THE COLUMNS MATCHED IN THE DATA SCHEMA?
The column names provided in the schema input from top to bottom are order-matched to the columns in the actual data from left to right. This ensures that the utility can identify the columns in the correct order even when the actual data does not contain column names.
Workato only returns an error when the number of columns between the schema and the actual data do not match.
Click Add data source to add more data sources. This allows you to compile required data for the transformation.
# Example data source: CSV file content from AWS S3 connector
In this example the data source is named employee and the data is fetched from file content coming from an S3 download file action. The schema contains employee-related information, and the CSV data uses a , (comma) as the delimiter.
Additionally, the user has chosen to ignore the CSV header row.
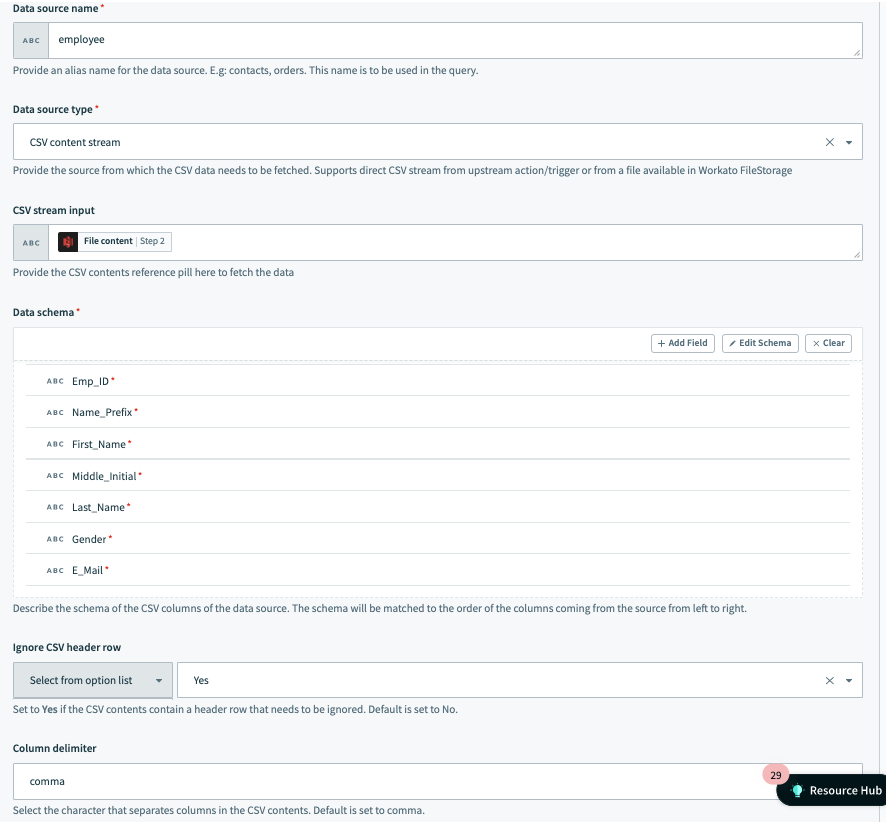 Data source example setup 1
Data source example setup 1
# Example data source: CSV file stored in Workato FileStorage
In this example the data source is named zipcode and is fetched from a file stored in Workato FileStorage in the path SQL/zipcode_data.csv.
Similar to the preceding example, the column delimiter is a , (comma), and the user has chosen to ignore the CSV header row of the data from the file while running the query.
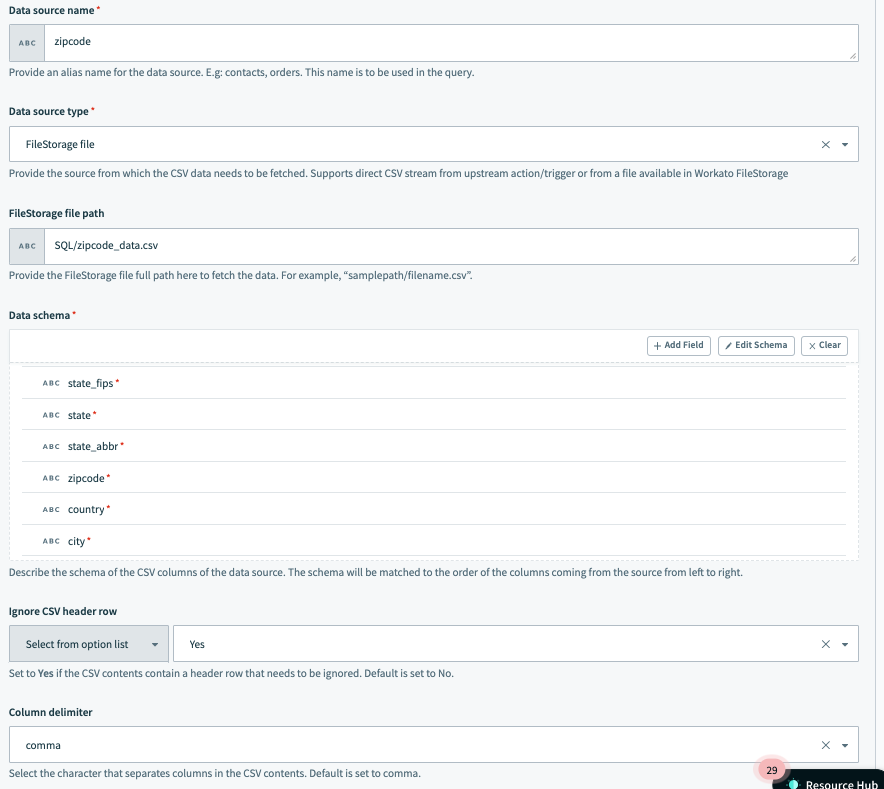 Data source example setup 2
Data source example setup 2
# Example data source: Excel file content from Google Drive connector
In this example, the data source is named sales_data. It retrieves data from an Excel file sourced from a Google Drive download file action. The schema is configured with sales-related columns, and the Excel data is obtained from the worksheet named Q1_Sales and the range A3:E100.
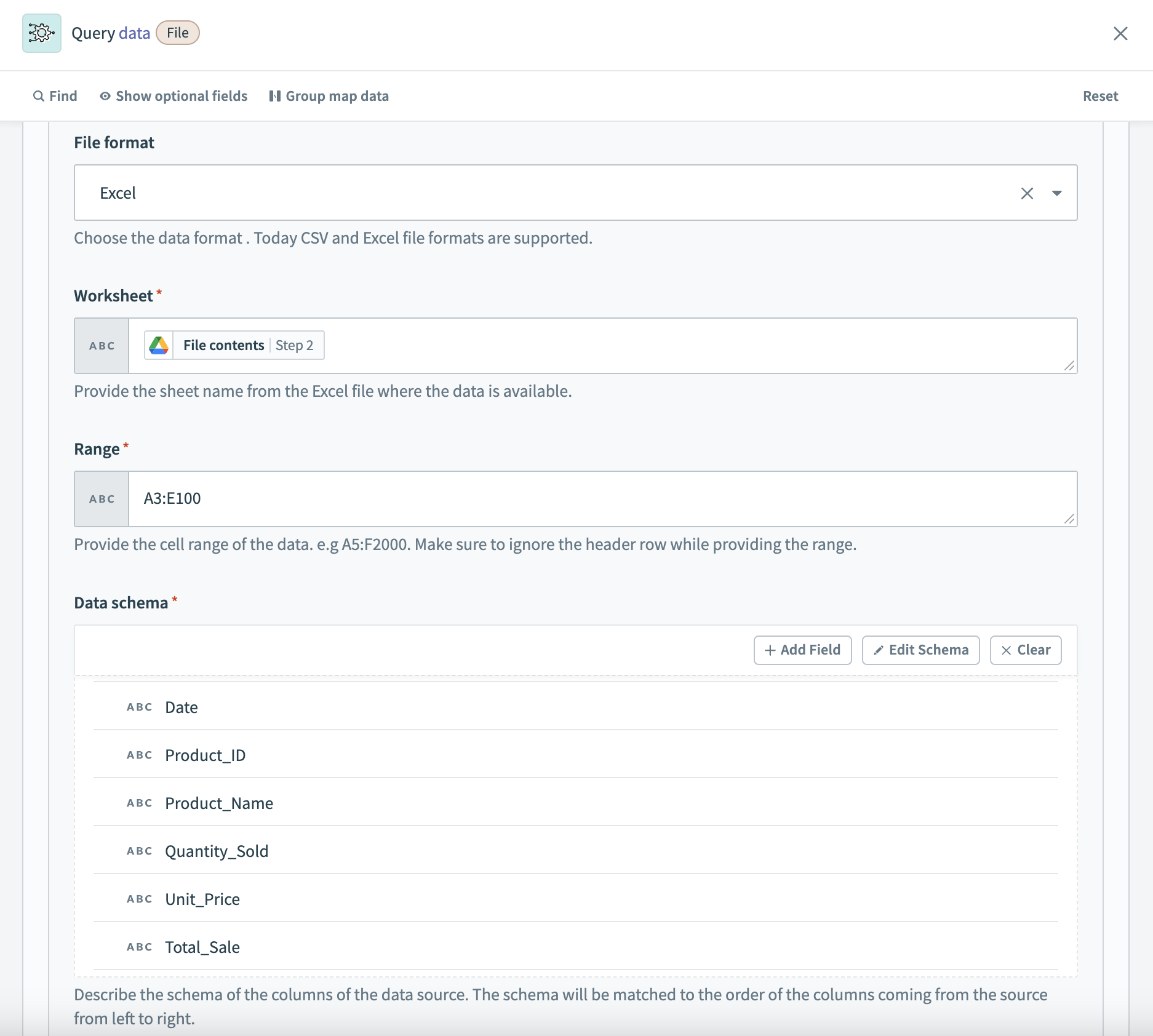 Data source example setup 3
Data source example setup 3
# Read next
Sample use cases
See our guides for step-by-step instructions on how to leverage SQL Transformations for the following use cases:
Last updated: 4/26/2024, 8:09:16 PM