# Salesforce bulk operations
Salesforce supports capabilities for bulk data load. Workato uses both the bulk V1.0 and bulk API 2.0 (opens new window) to support the loading of data in bulk from a CSV file into Salesforce. Supported operations are:
- Create objects in bulk via CSV file
- Update objects in bulk via CSV file
- Upsert objects in bulk via CSV file
- Retry objects bulk job in Salesforce via CSV file
- Search records in bulk using SOQL query
Users are recommended to use the bulk v2.0 actions as far as possible: they are more efficient and help batch records quickly and more effectively. This generally translates to less burden on the Salesforce org's bulk API limits.
Workato also supports synchronous batch operations to create and update objects in batches (max size of 2000 per batch).
TIP
All Salesforce bulk operations are asynchronous operations. The bulk job is sent to Salesforce and the recipe then polls every 5 mins for the result. Note that this means recipes must be started and not tested to allow Workato to continue polling for the results.
# Permissions required
The Manage Data Integrations, View Setup and Configuration and API Enabled permissions are required on the connected Salesforce User's account to allow all bulk operations to work correctly. Please note that you need to be the system administrator to enable these permissions. View this document (opens new window) for more information.
# Create/update/upsert objects in bulk via CSV file
There are 4 main sections/components in these bulk actions.
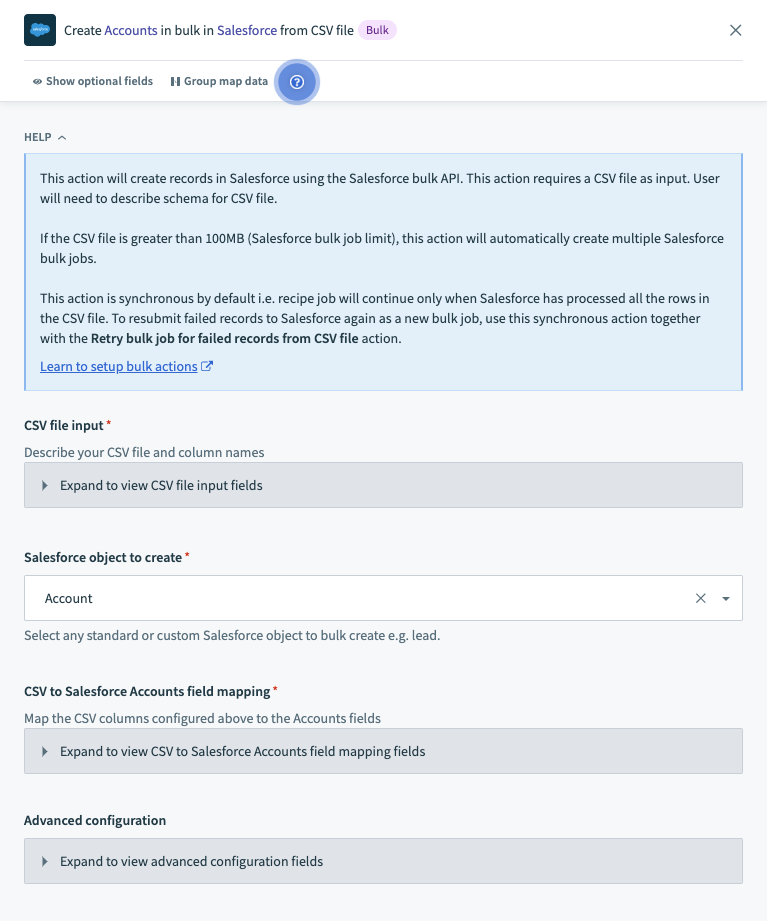 Salesforce bulk create via CSV file action sections
Salesforce bulk create via CSV file action sections
| Action section | Description |
|---|---|
| CSV file input | Define the schema of the CSV files containing Salesforce bulk load data. |
| Salesforce object to create/update/upsert | Define the Salesforce object to write to. Includes Primary key (usually external ID) for upsert operations. |
| Relationship fields | Describe how the CSV data columns should map into Salesforce object fields. Note that relationship fields need to be utilized to support polymorphic columns. More details on polymorphic fields can be found here (opens new window) |
| Advanced configuration | Define the size per Salesforce bulk job. Define whether this action should be synchronous or asynchronous. |
Let's go into each section in detail.
# CSV file input
In this section, define the schema of the CSV files containing Salesforce bulk load data. This enables Workato to read and extract data from your CSV files and move it into Salesforce accurately.
| Input field | Description |
|---|---|
| File content | Provide the CSV file content here. This would typically be a datapill from a Download file action or from a New file trigger. |
| Column separator | Describe the delimiter of your file - this can be comma, tab, colon, pipe, or space. |
| Contains header line? | Describe whether the CSV file content you're providing contains a header line or not. This will tell Workato whether to skip the first line for processing, because we don't want to inaccurately process header lines as data. |
| Columns names | Describe the names of the data columns in your CSV file. This will be used to generate the available CSV data for mapping into Salesforce in the CSV to Salesforce field mapping section. |
This is how the section should look after configuration.
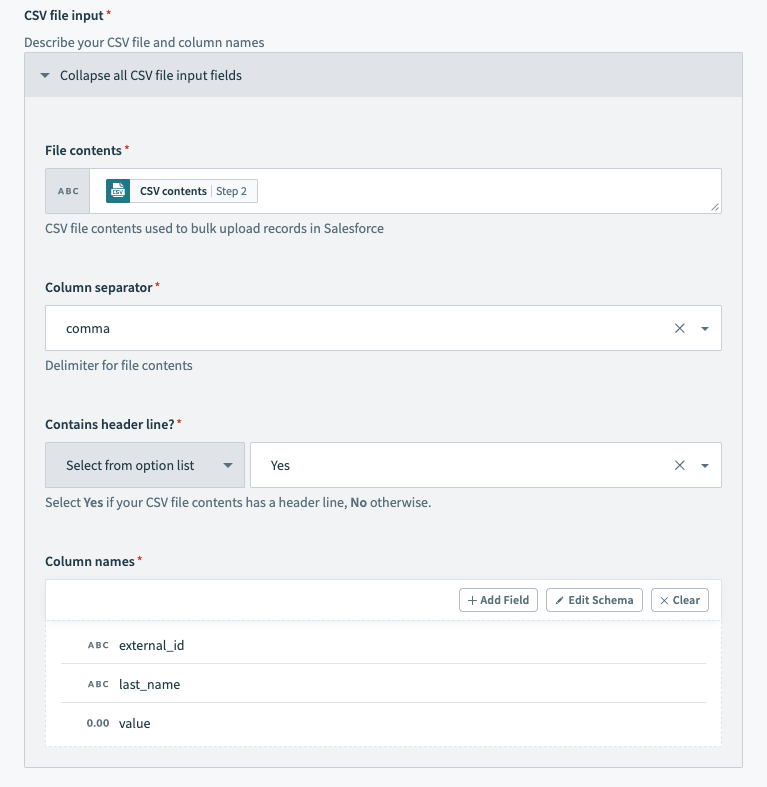 Salesforce bulk action - configured CSV file input section
Salesforce bulk action - configured CSV file input section
In our example, we used the sample CSV file below.
external_id,last_name,value
"a0K1h000003fXSS","Minnes","54"
"a0K1h000003fehx","Lecompte","12"
"a0K1h000003fjnv","Fester","28"
# Salesforce object to create/update/upsert
For the create and update operations, select the Salesforce object you wish to write to.
 Salesforce bulk create action - configured Salesforce object section
Salesforce bulk create action - configured Salesforce object section
For the upsert operations, select the Salesforce object you wish to write to as well as the Primary key of the object. A primary key in Salesforce is a unique identifier for each record. In order to carry out the bulk upsert action, your Salesforce object should have an External ID field.
The External ID field is a custom field that has the “External ID” attribute. It contains unique record identifiers from a system outside of Salesforce. External ID fields must be Custom text, number, or email fields.
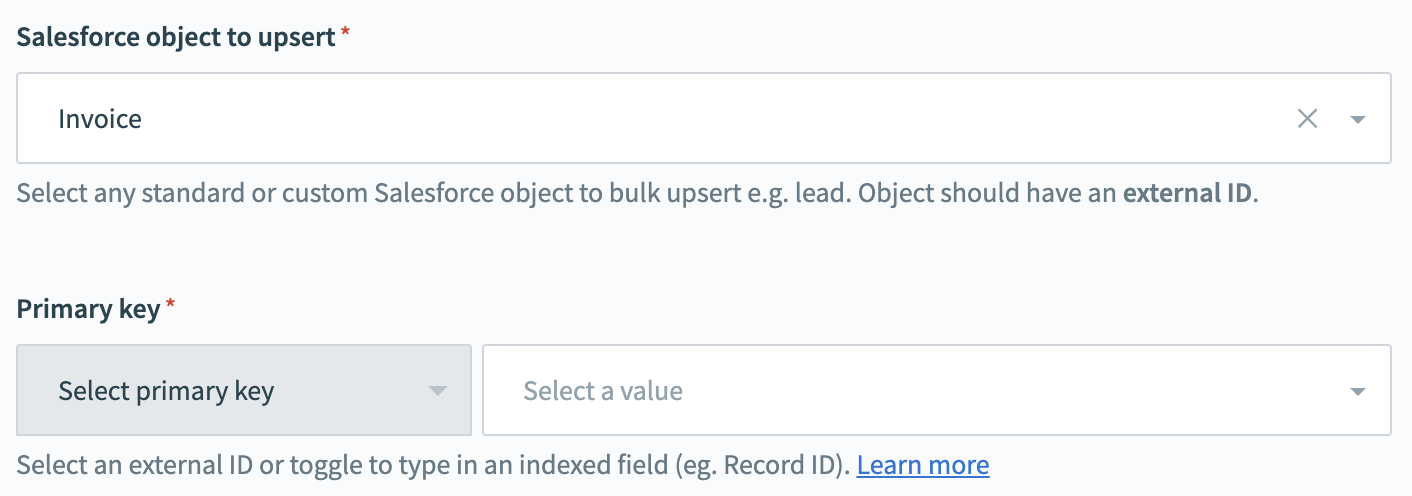 Salesforce bulk upsert action - configured Salesforce object section
Salesforce bulk upsert action - configured Salesforce object section
The bulk API for upsert also allows the use of other fields such as the internal Record ID in bulk upsert operations. Please note that these must be indexed fields. To use an indexed field, toggle the 'Primary key' to accept text input and type in the API name of the field.
The behavior while using an external ID and other indexed fields differ as follows:
| Input value | External ID | Indexed fields |
|---|---|---|
| Match found | Updates record | Updates record |
| No match found | Creates record | MALFORMED_ID:Id in upsert is not valid error |
| No value | MISSING_ARGUMENT:External_ID__c not specified error | Creates records |
# Relationship fields mapping
Many objects in Salesforce are related to other objects. For example, Account is a parent of Contact. You can add a reference to a related object in a CSV file by representing the relationship.
Relationship fields are also utilized to allow polymorphic column mapping. Workato cannot infer the mapping automatically and these need to be manually specified.
Some objects also have relationships to themselves. For example, the Reports To field for a contact is a reference to another contact.
When unconfigured, this section will not map any data into Salesforce.
For each field that you wish to write to in Salesforce, select which column of the CSV file the data should come from. This action does not allow datapills or data transformation via formula mode as it streams the CSV file data into Salesforce.
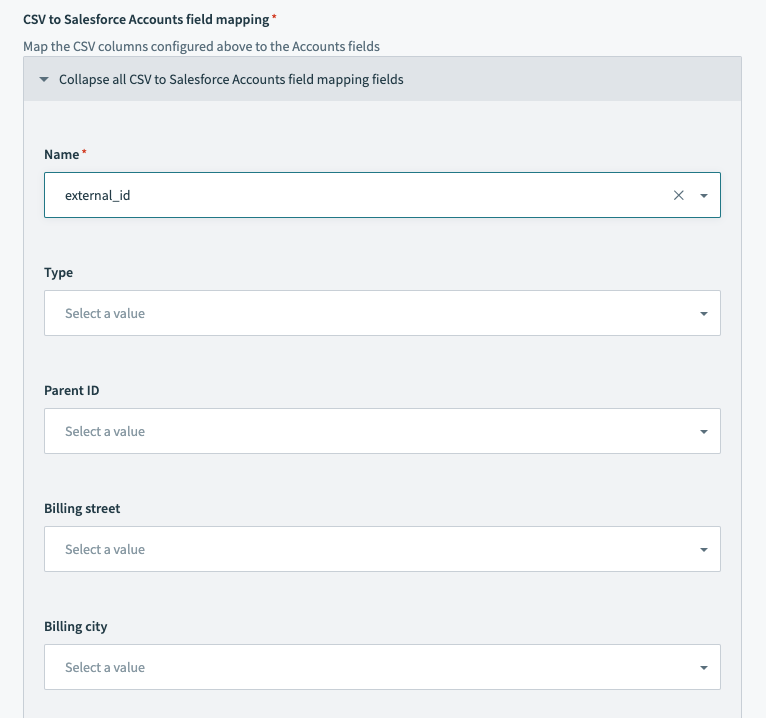 Salesforce bulk upsert action - field mapping section
Salesforce bulk upsert action - field mapping section
Learn more about relationship fields in a CSV header (opens new window).
# Advanced configuration
In this section, define whether the action should be synchronous or asynchronous. If synchronous, Workato waits for Salesforce to complete the bulk job processing before moving to the next recipe action. If asynchronous, Workato simply uploads the CSV file content into Salesforce and move to the next recipe action without waiting for Salesforce to complete the bulk job processing.
You can also define the size of the CSV file chunk per Salesforce bulk job. This defaults to 10 MB.
# Understanding the output datatree
The bulk operation's output datatree contains the following.
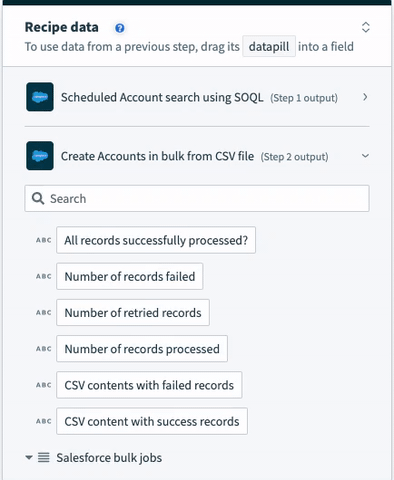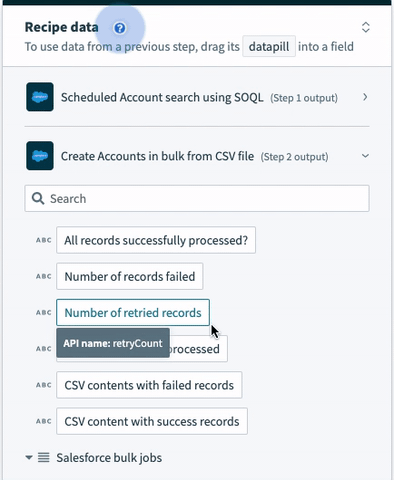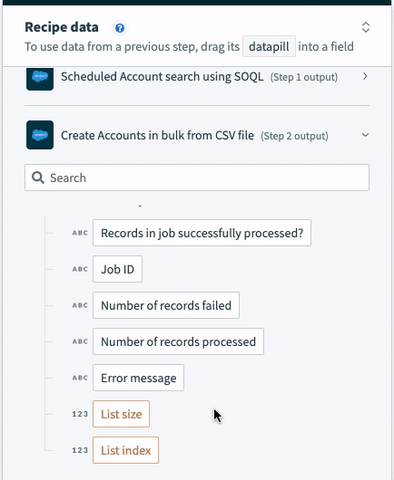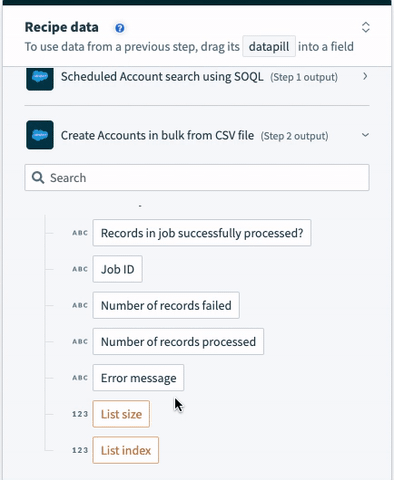 Salesforce bulk operation output datatree
Salesforce bulk operation output datatree
| Output datapill | Description | |
|---|---|---|
| All records successfully processed? | True if all CSV rows across Salesforce bulk jobs are processed successfully. False if any CSV rows across Salesforce bulk jobs failed. | |
| Number of records failed | Total number of CSV rows that failed to be successfully processed in Salesforce. | |
| Number of retried records | Total number of CSV rows that were retried to be processed in Salesforce. Only relevant for the retry action. | |
| Number of records processed | Total number of CSV rows that were processed in total by Salesforce (failed + succeeded). | |
| CSV content with failed records | CSV file content containing CSV rows in the original API request which failed to be successfully processed. 2 additional columns are added to this CSV file - **sf__Error** and **sf__Id**. Refer to the Salesforce documentation for more information. | |
| Salesforce bulk jobs | If CSV file is large, Workato will split the CSV file into chunks and process them as separate Salesforce bulk jobs to comply with Salesforce API size limits. Each bulk job in the list will have the following data. | |
| Job ID | Internal Salesforce ID of the Salesforce bulk job created | |
| Number of records failed | Number of records failed to be processed successfully by Salesforce | |
| Number of records processed | Number of records processed in total by Salesforce (i.e. number of rows in CSV file excluding header row) | |
| List size | Synthetic field that tells us how many Salesforce bulk jobs were created in total | |
The aggregated results across bulk jobs can be found at the top of the datatree.
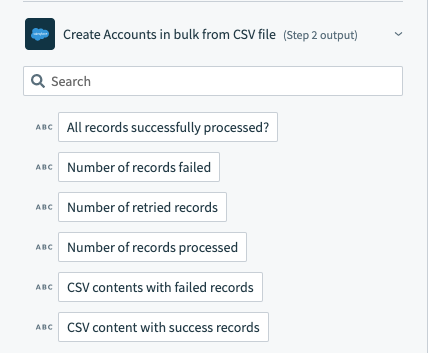 Salesforce bulk operation output datatree - aggregated results across bulk jobs
Salesforce bulk operation output datatree - aggregated results across bulk jobs
The list of Salesforce bulk jobs can be found at the bottom of the datatree.
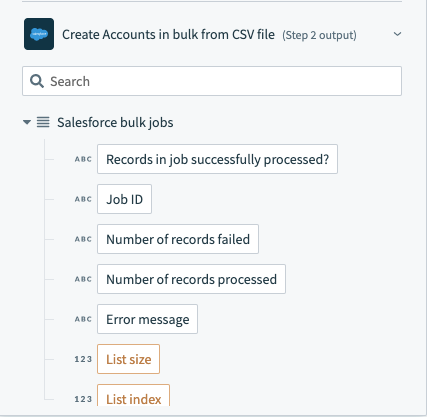 Salesforce bulk operation output datatree - list of bulk jobs
Salesforce bulk operation output datatree - list of bulk jobs
# Retry bulk job for failed records from CSV file
The retry action has a single input field CSV content with failed records that expects the CSV content with failed records datapill from a previous Salesforce bulk operation action. By passing that CSV content in, Workato will understand the previous configuration you have done (i.e. what your CSV file looks like, what Salesforce object to write to and how the CSV data should be mapped into Salesforce fields).
The retry action is synchronous. This means that the recipe will only continue to the next action when Salesforce has finished processing all CSV rows into Salesforce.
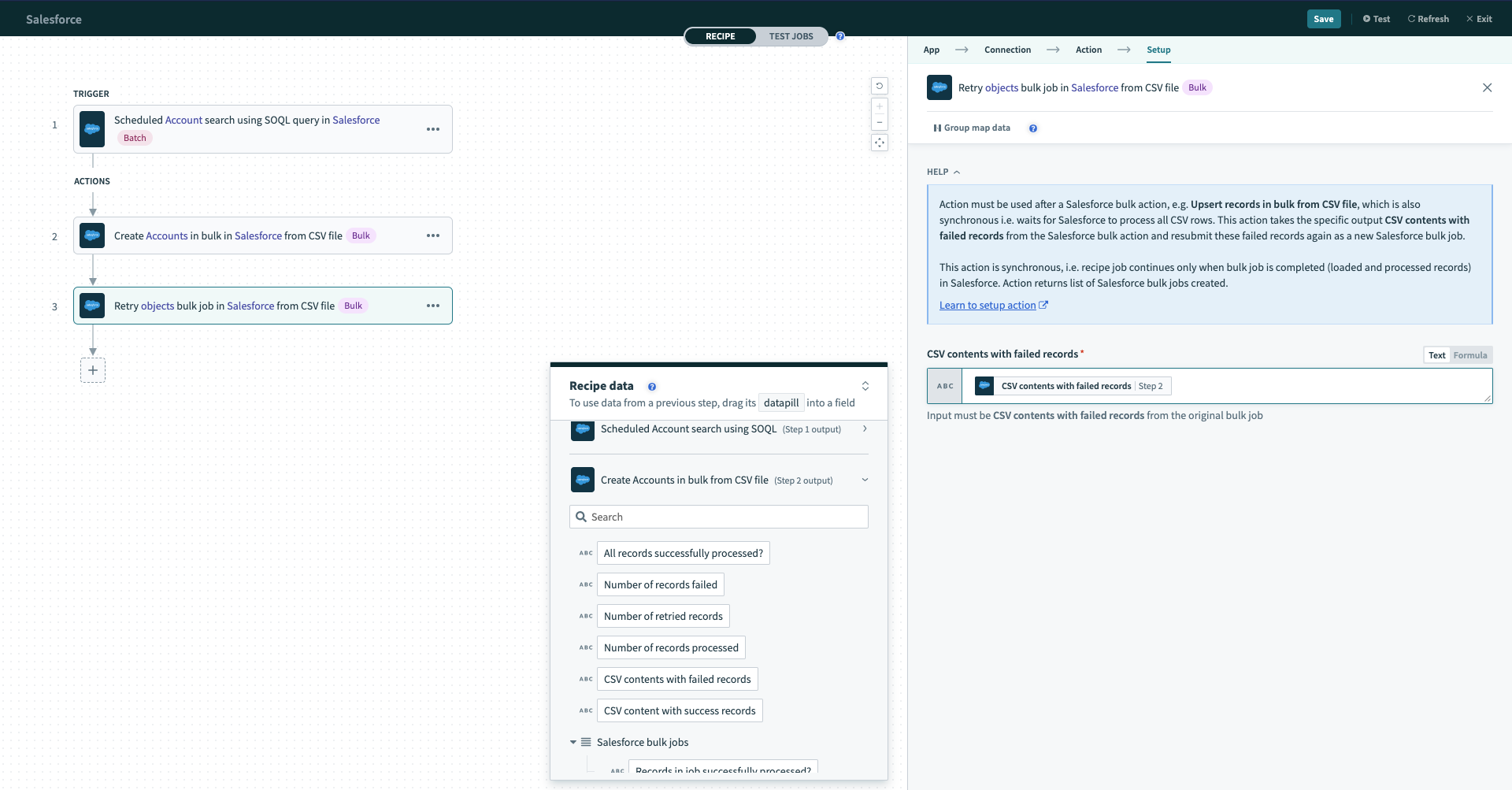 Configured Salesforce bulk retry action
Configured Salesforce bulk retry action
# Example recipe
Let's go through an example recipe using the bulk create via CSV file action as well as the retry bulk job action.
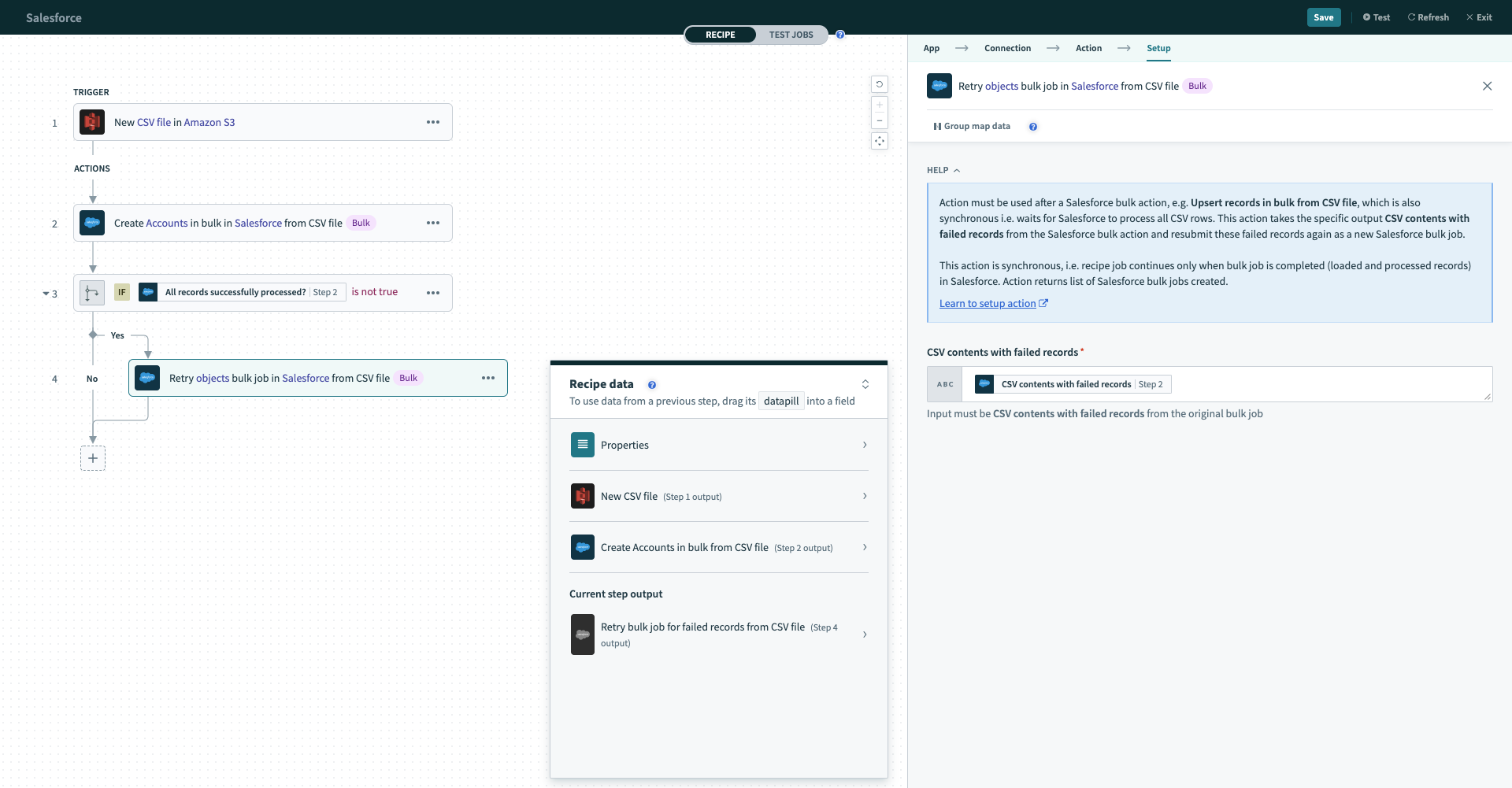 Sample recipe - Salesforce bulk upsert via CSV file. Example recipe (opens new window)
Sample recipe - Salesforce bulk upsert via CSV file. Example recipe (opens new window)
The S3 trigger monitors new CSV files dropped into an S3 bucket, and we stream the data from the CSV file into Salesforce via the Create objects in bulk via CSV file Salesforce action. If this create operation is not fully successful, i.e. at least 1 CSV row did not get written into Salesforce successfully, we use the Retry objects bulk job in Salesforce via CSV file action to attempt to write the failed CSV rows into Salesforce again.
The Salesforce actions Create objects in bulk via CSV file and Retry objects bulk job in Salesforce via CSV file will manage large files for you. For large CSV files over a couple of GBs in size, Workato will chunk the CSV file into sizes under the Salesforce bulk API size limits and create multiple Salesforce bulk jobs.
The CSV file we use is as follows.
external_id,billing_country,phone,account_number
"a0K1h000003fXSS","United States of America","123 456 789","54"
"a0K1h000003fehx","Canada","650 894 345","12"
"a0K1h000003fjnv","Japan","103 948 414","28"
Here is the configured bulk create action.
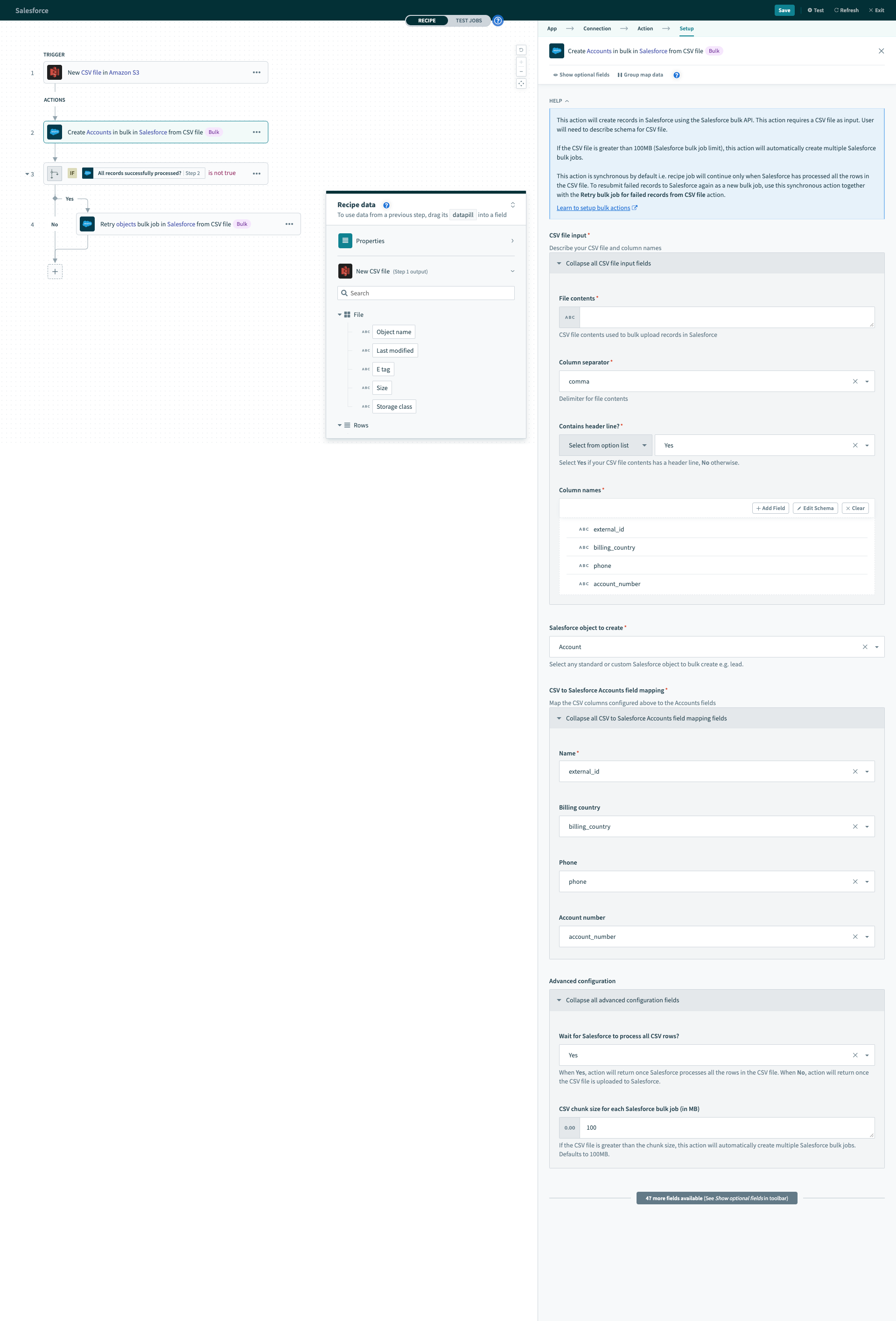 Configured Salesforce bulk upsert action
Configured Salesforce bulk upsert action
Subsequently, the recipe checks to see if any records failed to be processed successfully by Salesforce. this could be due to many reasons such as:
- Data errors
- Records were locked as someone else/another process was editing them
- Network issues
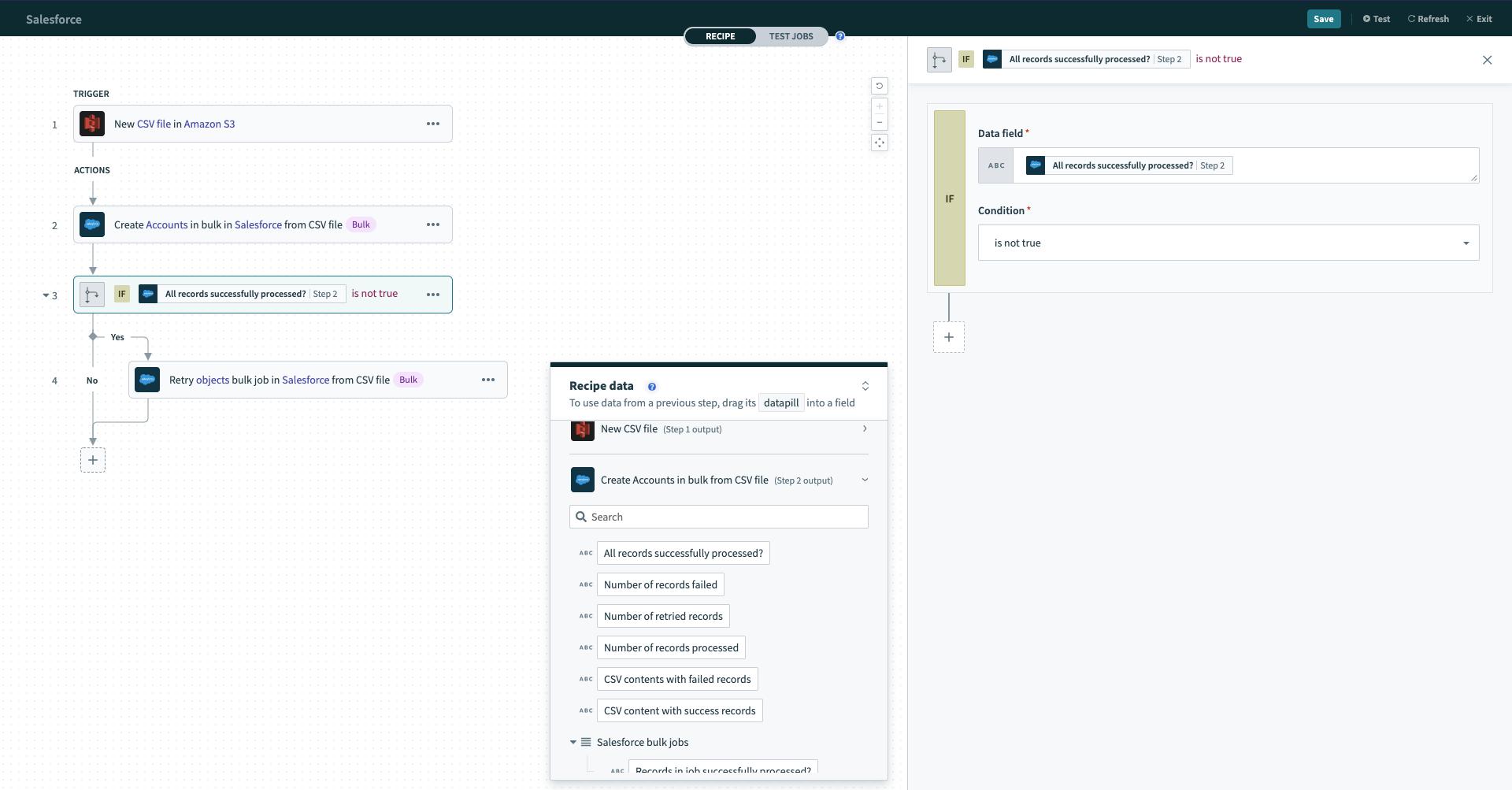 If condition checking for any failed records
If condition checking for any failed records
If any records failed, All records successfully processed? will be false, and the recipe will proceed to carry out the retry action.
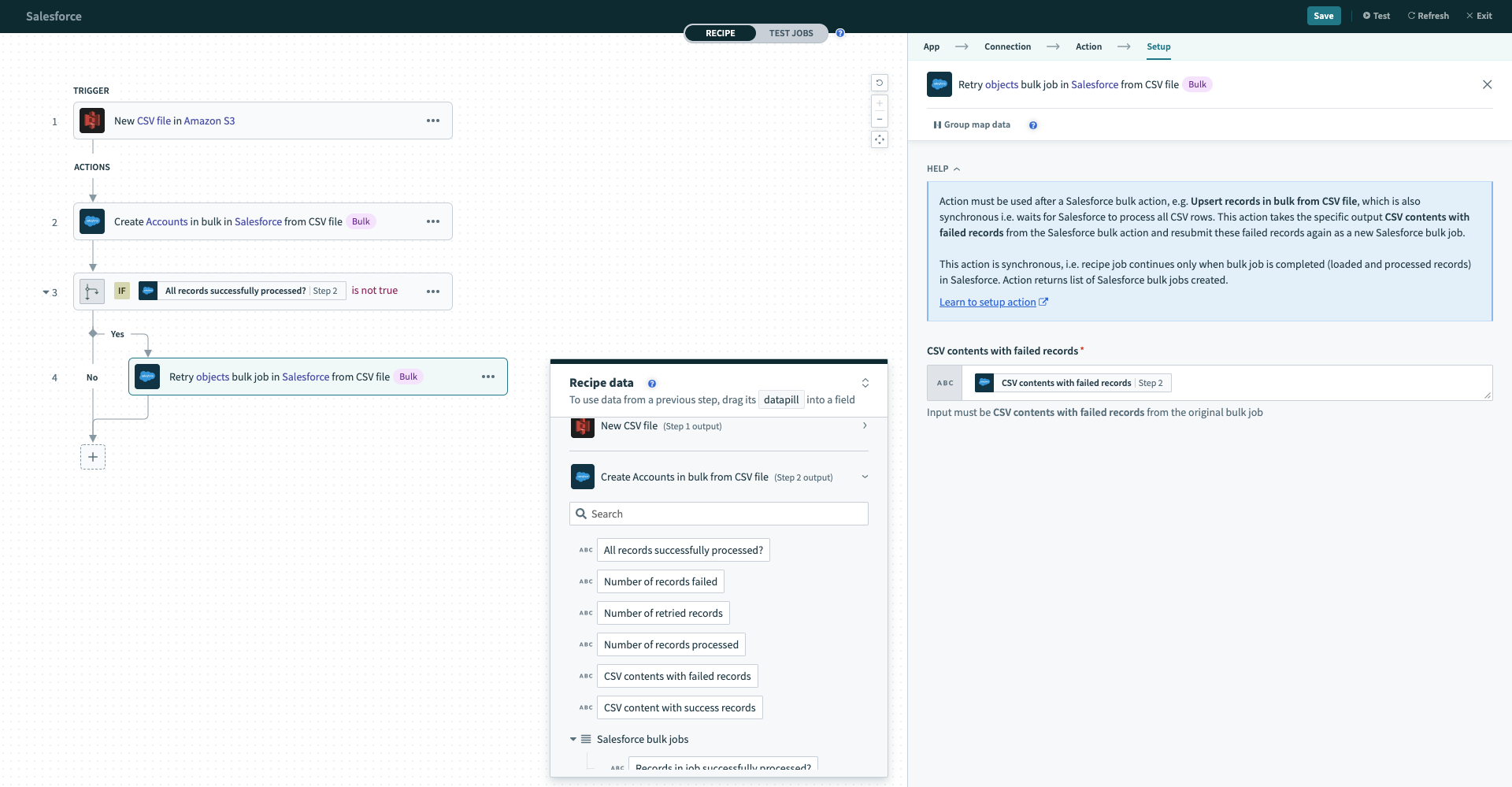 Configured retry bulk operation action
Configured retry bulk operation action
Last updated: 5/28/2023, 6:42:57 PM