# データ統合 - ETL/ELT
抽出、変換、ロード(ETL)および抽出、ロード、変換(ELT)は、データ統合およびデータウェアハウジングで使用されるプロセスであり、さまざまなソースからデータを抽出、変換、ロードしてデータウェアハウスやデータレイクなどのターゲット先に格納します。
このガイドでは、ELT/ETLの実用的なユースケースを説明付きのサンプルレシピで紹介します。
# バルク vs バッチ
バルク/バッチのアクション/トリガーはWorkato全体で利用できます。バルク処理は、ETL/ELTに特に適した大量のデータを1つのジョブで処理する能力を提供します。バッチ処理はバッチサイズとメモリ制約によって制限され、一般的にETL/ELTの文脈では適していません。
# 抽出、変換、ロード(ETL)
ETLは抽出フェーズから始まり、データベース、ファイル、API、Webサービスなどの複数の異種ソースからデータを取得します。この生データは変換フェーズ(クレンジング、フィルタリングなど)にさらされ、最終的には通常データウェアハウスなどのターゲットシステムにロードされます。
# サンプルETLレシピ
サンプルレシピのコピーはこちら (opens new window)で見つけることができます。
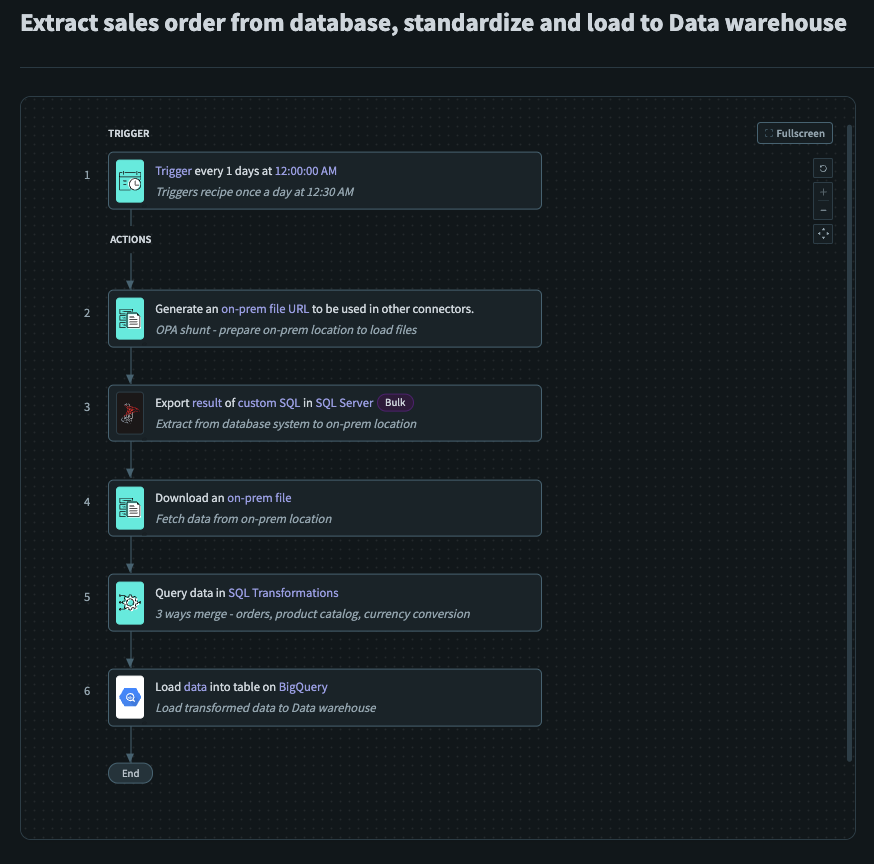 サンプルETLレシピ
サンプルETLレシピ
# レシピの詳細
サンプルETLレシピは、オンプレミスデータソース(SQL Server (opens new window))からデータを抽出し、Workato FileStorage (opens new window)に格納された製品カタログと結合し、この変換された出力をデータウェアハウス(BigQuery (opens new window))にロードする方法のセットアップです。さらに、Workatoのファイルストリーミング機能を使用すると、時間やメモリの制約を気にすることなくデータを転送できます。このレシピは、ETLレシピを構築する際の一般的なガイドとして機能し、オンプレミスデータソースから抽出したデータに基本的な変換を行い、それらをデータウェアハウスにロードします。
# セットアップ
このレシピには、裏側で追加の手順は必要ありません。
このレシピは、毎日0030にスケジュールされたトリガーで起動します。このトリガーは使用ケースに合わせてカスタマイズする必要があります。
Generate On-Prem File URL (opens new window) を使用して、後続のファイルのロード先となるオンプレミスの場所を準備しました。
Export Query Result (Bulk) (opens new window) を使用して、SQL Serverから必要な売上データを前のステップで指定したオンプレミスの場所に抽出しました。
- 以前に作成したオンプレミスファイルにデータをロードします
Download an On-Prem File (opens new window) を使用して、以前に指定したオンプレミスの場所から売上データを取得しました。
- 以前に作成したオンプレミスファイルからCSVコンテンツを取得します
Query Data using SQL Transformations (opens new window) を使用して、売上データをWorkato FileStorage (opens new window)から取得した製品データとマージしました。
- 売上データと製品データをマージして、ビジネス要件に適した変換された出力を生成します
Load Data into BigQuery (opens new window) を使用して、変換されたデータをデータウェアハウスにロードしました。
- 変換された出力をデータウェアハウスに最終的にロードします
# 抽出、ロード、変換(ELT)
ETLと同様に、ELTも抽出フェーズから始まり、さまざまなソースからデータを抽出します。ELTは、抽出したデータをデータレイクや分散ストレージなどのターゲットシステムにロードすることに重点を置いています。データがロードされると、変換はターゲットシステム内で行われます。
# サンプルELTレシピ
サンプルレシピのコピーはこちら (opens new window)で見つけることができます。
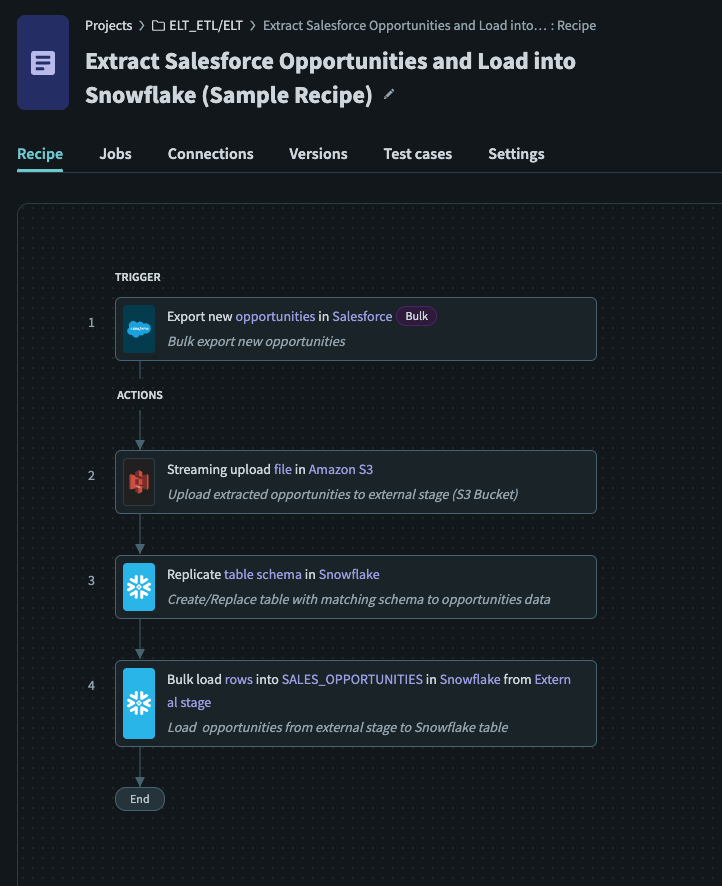 サンプルELTレシピ
サンプルELTレシピ
# レシピの詳細
サンプルELTレシピは、クラウドデータソース(Salesforce)からデータをデータウェアハウス(Snowflake)に抽出する方法のセットアップです。このレシピは、ELTレシピを構築する際のガイドとして機能し、クラウドデータソースから大量のデータを抽出し、データベースにロードする基本的な機能を実行します。
# セットアップ
- 必要な権限を持つSnowflake上の外部ステージを設定している必要があります。詳細はこちら (opens new window)
トリガーとして**新規/更新レコードのエクスポート(バルク)**を使用して、新しいレシピを作成します。
- ユースケースに応じてトリガーを設定します
- バルクアクションは、1つのジョブで大量のデータを抽出するのに最適です
S3ファイルストリーミングのアップロード (opens new window) アクションを使用して、抽出したCSVファイルの内容を指定されたS3バケットにアップロードしました。
- アクションは、抽出したデータを指定されたS3バケットにストリーミングします
Snowflakeスキーマの複製 (opens new window) アクションを使用して、新しい/既存のテーブルを作成/更新しました。
- このステップはオプションです。ステージングされたデータのスキーマに一致する既存のテーブルがある場合、このステップは必要ありません
- スキーマの複製により、Snowflakeの宛先テーブルのスキーマが存在し、またはソースデータに適合する適切なスキーマがあることが保証されます。
外部ステージからテーブルへのデータのバルクロード (opens new window) を使用して、ステージングされたファイルからデータを既存のテーブルにロードしました。
- 前のステップで設定したステージングファイルからデータを既存のテーブルにロードします。ロードは
COPYコマンドを使用して行われます。
データ変換
このレシピでは、Snowflakeでのデータ変換の方法は示されていません。データ変換は、データをテーブルにロードした後、またはそれ以前に行うことができます。詳細はこちら (opens new window)を参照してください。
Last updated: 2024/2/13 16:59:53