# SQL Server - New/updated row (新規行/更新行) トリガー
# New/updated row (新規行/更新行)
このトリガーは、選択したテーブルまたはビューに挿入/更新される行を取得します。各行は別個のジョブとして処理されます。ポーリング間隔ごとに新規行/更新行をチェックします。
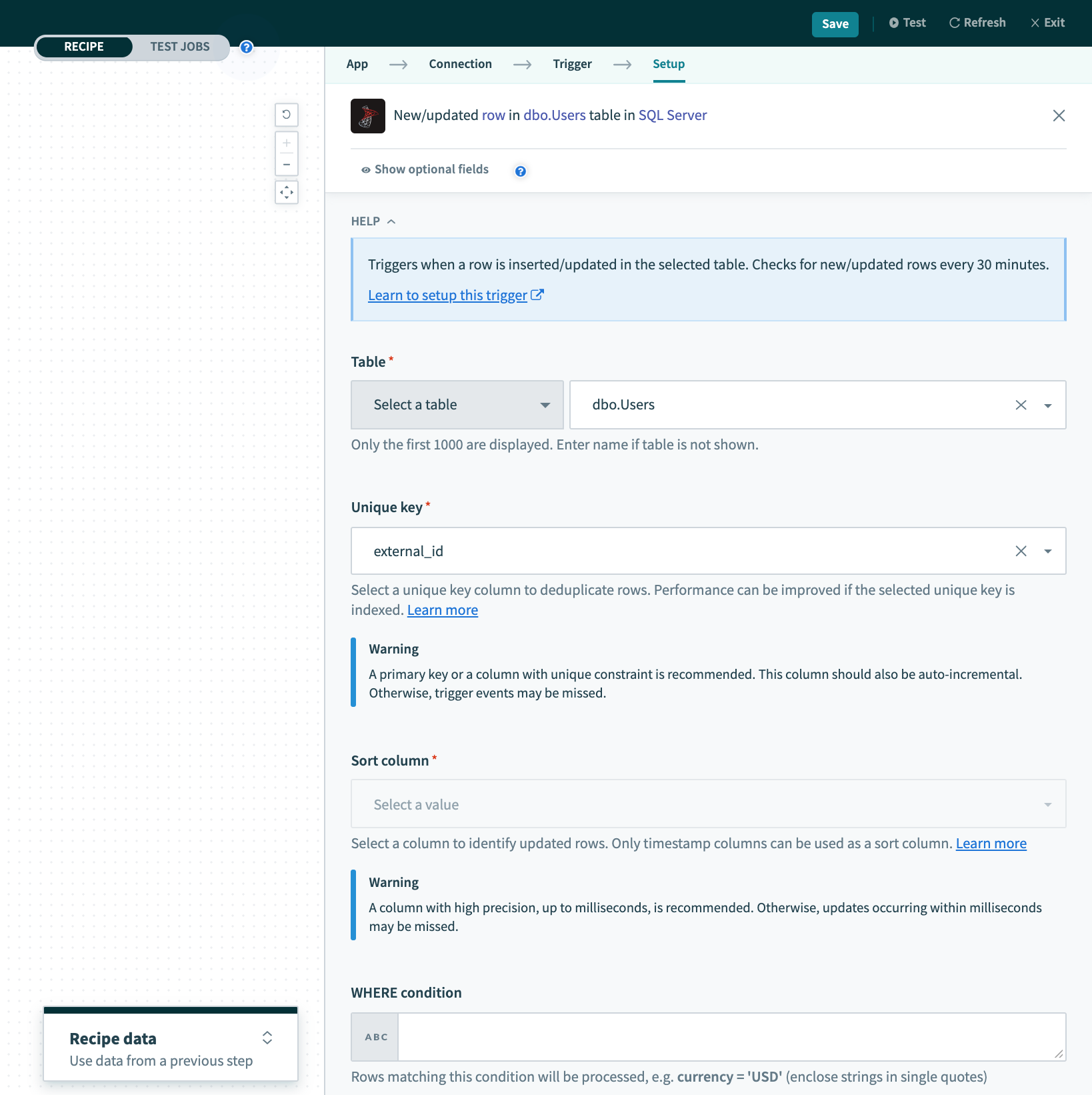 New/updated row トリガー
New/updated row トリガー
| 入力項目 | 説明 |
|---|---|
| Table | 行を処理するテーブル/ビューを選択します。 |
| Unique key | 行を一意に識別する一意のキー列を選択します。この列のリストは、選択したテーブル/ビューから生成されます。 |
| Sort column | 更新される行を識別する列を選択します。 |
| Where condition |
行をフィルタリングするためのオプションの WHERE 条件を入力します。
|
# New/updated batch of rows (新規行/更新行のバッチ)
このトリガーは、選択したテーブルまたはビューに挿入/更新される行を取得します。これらの行は、ジョブごとに行のバッチとして処理されます。このバッチサイズは、トリガーの入力で設定できます。ポーリング間隔ごとに新規行/更新行をチェックします。
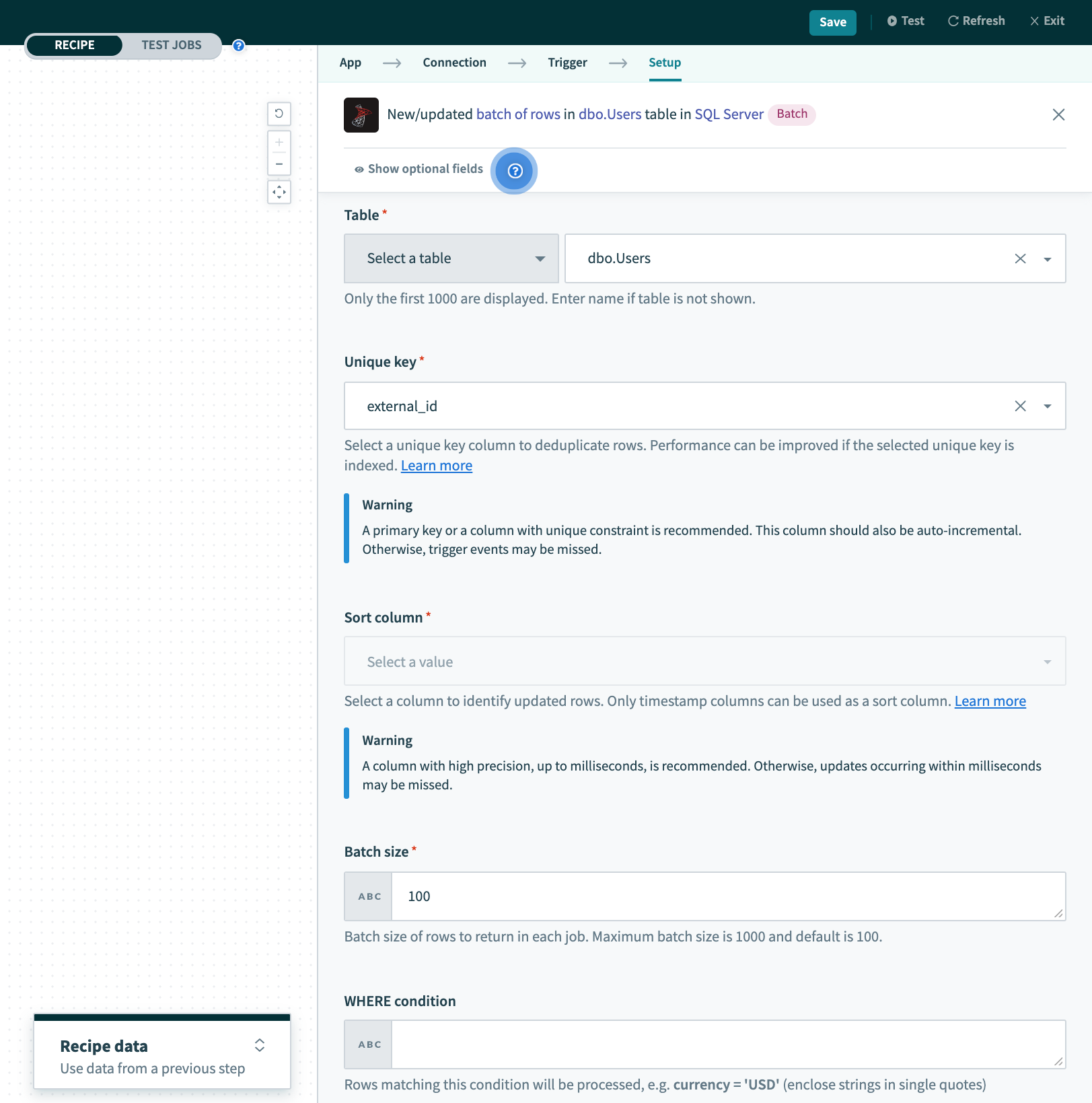 New/updated batch of rows トリガー
New/updated batch of rows トリガー
| 入力項目 | 説明 |
|---|---|
| Table | 最初に、行を処理するテーブル/ビューを選択します。 |
| Unique key | 行を一意に識別する一意のキー列を選択します。この列のリストは、選択したテーブル/ビューから生成されます。 |
| Sort column | 更新される行を識別する列を選択します。 |
| Batch size | このレシピの各ジョブで処理するバッチサイズを設定します。 |
| WHERE condition |
行をフィルタリングするためのオプションの WHERE 条件を入力します。
|
# New/updated batch of rows via custom SQL (カスタム SQL を介した新規行/更新行のバッチ)
このトリガーは、カスタム SQL に一致する行が挿入/更新されたときに行を取得します。これらの行は、ジョブごとに行のバッチとして処理されます。このバッチサイズは、トリガーの入力で設定できます。ポーリング間隔ごとに一度、新規行をチェックします。
# サポートされるバージョン
このトリガーは SQL Server 2012以降でのみサポートされています。SQL Server 2012以降でのみ利用可能なデフォルトのストアドプロシージャ sp_describe_first_result_set が使用されます。
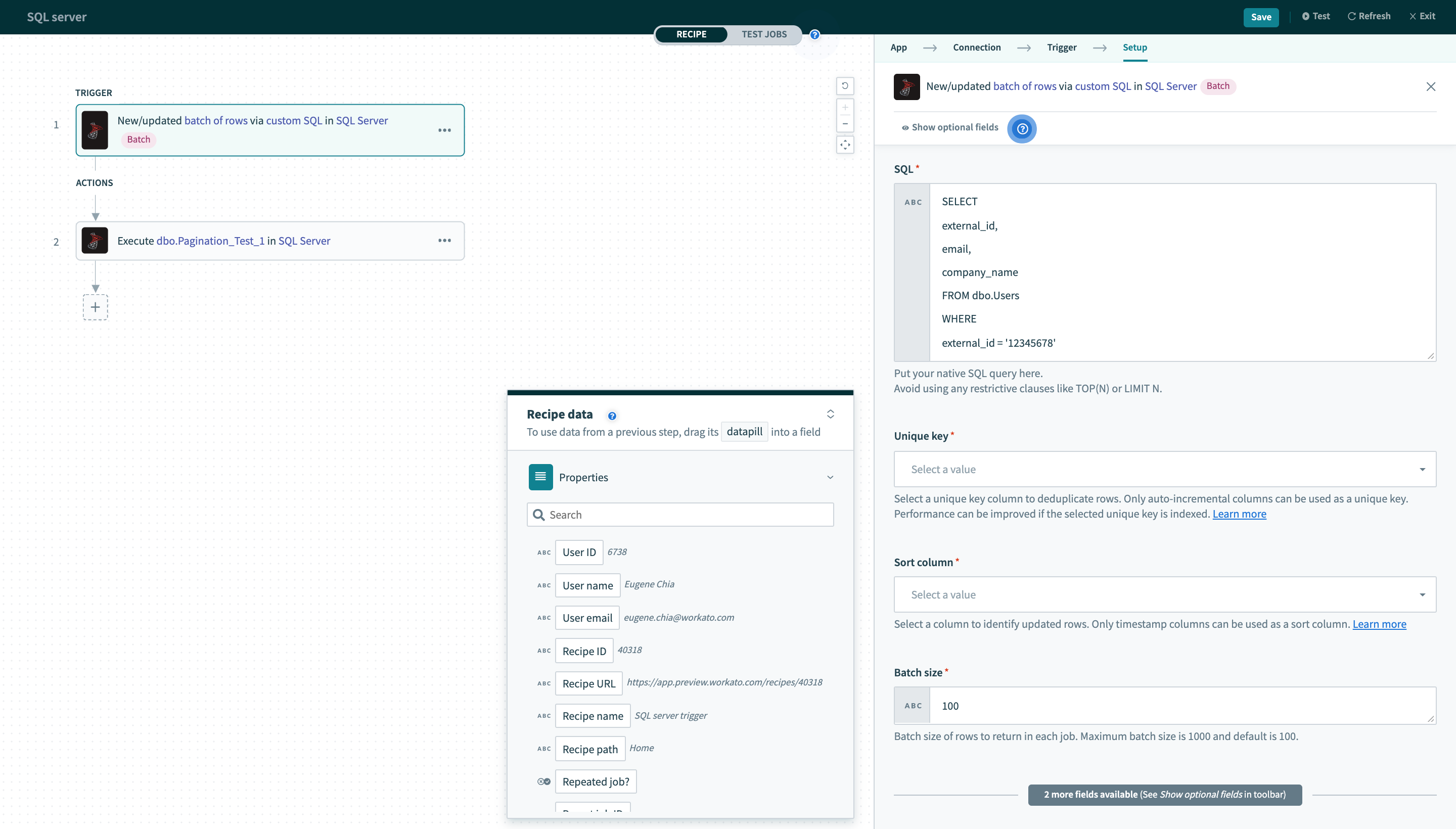 New/updated batch of rows trigger via custom SQL
New/updated batch of rows trigger via custom SQL
このトリガーは SQL Server 2008以前のバージョンではサポートされていません。
| 入力項目 | 説明 |
|---|---|
| SQL | 新規行を取得するためにポーリング間隔ごとに実行されるカスタム SQL クエリー |
| Unique key | 行を一意に識別する一意のキー列を選択します。この列のリストは、指定したカスタム SQL から生成されます。 |
| Sort column | 更新される行を識別する列を選択します。 |
| Batch size | このレシピの各ジョブで処理するバッチサイズを設定します。このサイズは、デフォルトでは100に設定されます。 |
# 入力項目
# Table
行を処理するテーブル/ビューを選択します。このためには、ピックリストからテーブルを選択するか、または入力項目をテキストモードに切り替えて完全なテーブル名を入力します。
# Unique key
選択したこの列の値は、選択したテーブル内で行の重複を削除するために使用されます。
そのため、選択した列内の値はテーブル内で繰り返されません。通常、この列はテーブルのプライマリキー (ID など) になります。この列は増分列で、並べ替え可能です。また、パフォーマンス向上のためにインデックスを付けることもできます。
PRIMARY KEY または UNIQUE 制約を持つ列のみを使用できます。この SQL クエリーを実行して、この要件を満たす列を見つけます。
SELECT col.column_name
FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE col
JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS c ON c.constraint_name = col.constraint_name
WHERE
c.constraint_type IN ('PRIMARY KEY','UNIQUE') AND
c.table_schema='schema_name' AND
c.table_name='table_name'
列が見つからない場合は、そのような列を作成する方法についてのベストプラクティスを確認してください。
# Sort column
これは、テーブル内の行が更新されるたびに更新される列です。通常はタイムスタンプ列になります。
行の更新時、[Unique key] の値は変わりません。ただし、この値のタイムスタンプは、最後の更新日時を反映するよう更新されます。このロジックに従い、Workato ではこの列の値を、選択した [Unique key] 列の値と合わせて追跡します。 [Sort column] の値の変更が検出されると、更新された行のイベントがトリガーにより記録され、処理されます。
datetime2 および datetime の列のタイプのみを使用できます。この SQL クエリーを実行して、この要件を満たす列を見つけます。
SELECT column_name
FROM INFORMATION_SCHEMA.COLUMNS
WHERE
table_schema='table_schema' AND
table_name='table_name' AND
data_type in('datetime', 'datetime2')
列が見つからない場合は、そのような列を作成する方法についてのベストプラクティスを確認してください。
# Batch size
各ジョブで返される行のバッチサイズ。これには、 1 ~最大バッチサイズ間の任意の数を指定できます。最大バッチサイズは 100 で、デフォルトは 100 です。
指定されたポーリングにおいて、行数が設定されたバッチサイズよりも少ない場合、このトリガーはすべての行をサイズの小さなバッチとして処理します。
# WHERE condition
この条件は、1つ以上の列の値に基づいて行をフィルタリングするために使用されます。
status = 'closed' and priority > 3
選択したテーブルのすべての行を処理するには、空白のままにしてください。
サブクエリーを含む複雑な WHERE 条件を使用することもできます。詳細については、WHERE 条件に関するガイドを参照してください。
# SQL
行を選択するために実行する SQL を指定します。ここで指定する SQL は、出力データツリーの生成に使用されます。これを生成するために、SQL クエリーは指定時に一度実行されます。データピルをここにマッピングして、動的に変化する SQL 文を実行できます。データピルは必ず引用符 ('') で囲んでください。
SQL で TOP のような制限句を使用しないでください。これは、クエリーで返される行数の制限が、 [Batch size] 入力項目で定義される値に基づいているためです。独自の制限句を追加すると、このアクションは失敗します。
Last updated: 2023/8/31 1:07:14